2026년 4월 최신 LLM 벤치마크 통합 비교 분석 (GPT-5.5, Opus 4.7, DeepSeek V4)

2026년 4월 하순, 불과 열흘 사이에 주요 LLM들이 연달아 출시되면서 공식 리포트상의 비교 수치만으로는 현시점의 정확한 서열을 확인하기 어려워졌습니다.
각 모델의 출시 시점이 겹치다 보니, 제조사들이 발표한 벤치마크는 상대방의 이전 버전(예: GPT-5.5 리포트 내 Claude 4.6 비교 등)을 기준으로 작성되어 있습니다. 이에 4월 24일 기준, 가장 최신 데이터들을 직접 취합하고 정규화하여 통합 비교 분석을 정리했습니다.
2026년 4월 최신 LLM 벤치마크 통합 분석 (GPT-5.5 / Opus 4.7 / DeepSeek V4)
최근 2주간 주요 AI 모델들이 연이어 출시되었습니다.
- 4월 16일: Claude Opus 4.7 출시
- 4월 23일: GPT-5.5 출시
- 4월 24일: DeepSeek V4 출시
각 제조사가 공개한 벤치마크는 출시 시점 차이로 인해 서로의 구버전 모델을 대조군으로 삼고 있습니다. 본 리뷰는 이러한 시차를 제거하고, 현시점 각 모델의 최신 버전 데이터를 동일 선상에서 비교하기 위해 지표를 통합·정규화한 결과를 바탕으로 합니다.
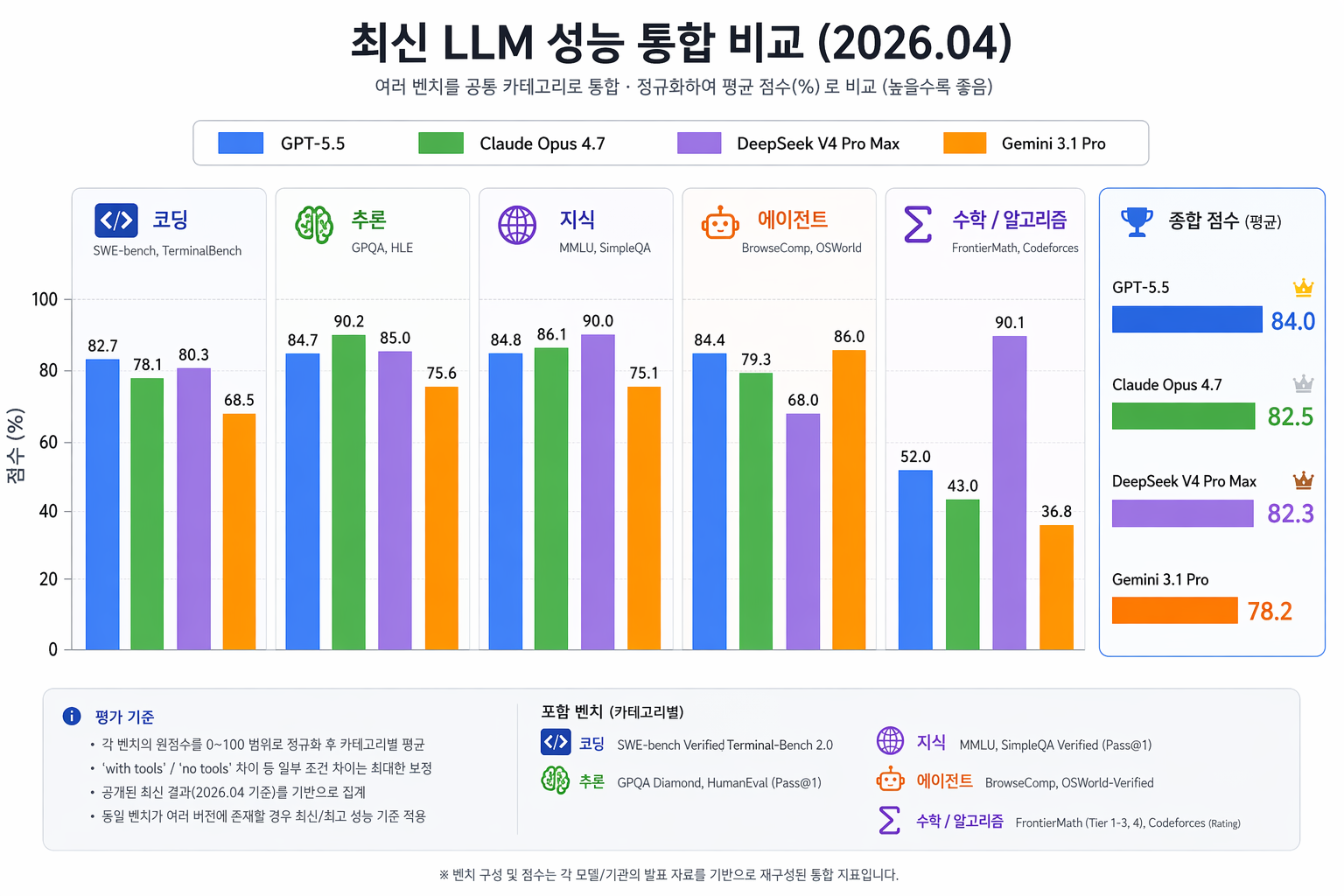
1. 종합 성능 비교 (2026.04.24 기준)
각 영역별 벤치마크 점수를 0~100 범위로 정규화하여 산출한 종합 평균 점수입니다.
| 모델명 | 출시일 | 종합 점수 (평균) |
|---|---|---|
| GPT-5.5 | 04.23 | 84.0 |
| Claude Opus 4.7 | 04.16 | 82.5 |
| DeepSeek V4 Pro Max | 04.24 | 82.3 |
| Gemini 3.1 Pro | - | 78.2 |
2. 부문별 세부 지표 분석
🖥️ 코딩 (Coding)
- GPT-5.5 (82.7%):
SWE-bench,Terminal-Bench 2.0등에서 가장 높은 성취도를 보입니다. 실무 개발 환경에서의 문제 해결 능력이 강조된 결과입니다. - DeepSeek V4 (80.3%): GPT와 근소한 차이로 뒤를 잇고 있습니다.
- Claude Opus 4.7 (78.1%): 이전 버전 대비 상승했으나 코딩 부문에서는 3위를 기록했습니다.
🧠 추론 (Reasoning)
- Claude Opus 4.7 (90.2%):
GPQA Diamond,HLE등 고난도 추론 영역에서 독보적인 수치를 기록했습니다. 복잡한 논리 구조를 다루는 데 강점이 있습니다. - DeepSeek V4 (85.0%) / GPT-5.5 (84.7%): 두 모델은 추론 영역에서 유사한 수준의 지표를 보여줍니다.
🌐 지식 및 Q&A (Knowledge)
- DeepSeek V4 (90.0%):
MMLU,SimpleQA등 지식 기반 벤치마크에서 가장 높은 정확도를 보입니다. - Claude Opus 4.7 (86.1%): 지식 영역에서도 상위권 지표를 유지하고 있습니다.
🤖 에이전트 (Agentic Capabilities)
- Gemini 3.1 Pro (86.0%):
OSWorld,BrowseComp등 외부 도구 활용 및 웹 브라우징 에이전트 성능에서 가장 높은 점수를 기록했습니다. - GPT-5.5 (84.4%): 범용 에이전트 실행 능력에서 Gemini와 대등한 수준을 보입니다.
➗ 수학 및 알고리즘 (Math & Algorithm)
- DeepSeek V4 Pro Max (90.1%):
FrontierMath및Codeforces레이팅에서 타 모델들을 압도하는 수치를 기록했습니다. 수리적 사고와 알고리즘 최적화에 특화된 지표를 보여줍니다. - GPT-5.5 (52.0%) / Claude Opus 4.7 (43.0%): 해당 카테고리에서는 DeepSeek 대비 낮은 수치를 기록하고 있습니다.
3. 기술적 요약
데이터 통합 분석 결과, 각 모델의 기술적 지향점은 다음과 같이 요약됩니다.
- GPT-5.5: 코딩과 에이전트 활용 등 실제 실행 중심의 작업에서 균형 잡힌 고성능을 유지합니다.
- Claude Opus 4.7: 고난도 논리 추론과 언어 이해가 필요한 영역에서 여전히 정밀한 성능을 보여줍니다.
- DeepSeek V4: 수학, 알고리즘, 지식 집약적 영역에서 기존 모델들의 지표를 크게 상회하는 수치를 나타냅니다.
- Gemini 3.1 Pro: 종합 점수는 낮으나 실시간 웹 검색 및 도구 연동 에이전트 분야에서 경쟁력을 유지하고 있습니다.
본 분석은 2026년 4월 말 기준의 최신 벤치마크 데이터를 통합한 결과이며, 각 모델의 업데이트에 따라 지표는 변동될 수 있습니다.
데이터 기반의 담백한 비교가 필요하신 분들께 도움이 되길 바랍니다.